@aerilius said:
@thomthom said:
Are you searching in Ruby or Javascript, Andreas?
I had implemented the exact search algorithms in JavaScript and Ruby. Ruby was significantly faster (but it shouldn't be any effort to switch to JavaScript).
I tried it with Unicode characters (that Ruby interpretes as two bytes) and it worked well. It seemed to me that it doesn't matter whether Ruby sees a double byte character or two single bytes, if the search word and the scanned string contain both the same Unicode characters (or double/multiple bytes).
I'll do more tests.
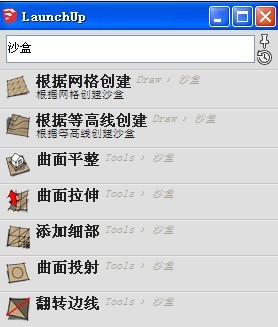
Only very smoothly sandbox tools search